Classification of Arabic Documents
Background
Text document classification (TC) is the process of assigning a given text to one or more categories. This process is considered as a supervised classification technique, since a set of labeled (pre-classified) documents is provided as a training set. The goal of TC is to assign a label to a new, unseen document[^1] .In order todetermine the appropriate category for an unlabeled text document,a classifier is used to perform the task of automatically classifyingthe text document. The rapid growth of the internet and computertechnologies has caused the existence of billions of electronic textdocuments which are created, edited, and stored in digital ways.This situation has brought great challenge to the public, specificallythe computer users in searching, organizing, and storing these documents.
TC is one of the most common themes in analyzing complex data. The study of automated text categorization dates back to the early 1960s. Then, its main projected use was for indexing scientific literature by means of controlled vocabulary. It was only in the 1990s that the field fully developed withthe availability of ever increasing numbers of text documents in digital form and thenecessity to organize them for easier use. Nowadays automatedTCis applied in a varietyof contexts - from the classical automatic or semiautomatic (interactive) indexingof texts to personalizedcommercials delivery, spam filtering, Web page categorizationunder hierarchical catalogues, automatic generation of metadata, detection oftext genre, and many others[^2] .
There are two mainapproaches to text categorization. The first is the knowledge engineering approach inwhich the expert’s knowledge about the categories is directly encoded into the systemeither declaratively or in the form of procedural classification rules. The otheris the machine learning (ML) approach in which a general inductive process buildsa classifier by learning from a set of pre-classified examples.
TC may be formalized as the task of approximating the unknown target function Φ: D × C → {T,F} (that describes how documents ought to be classified,according to a supposedly authoritative expert) by means of a functionΦ ̂ : D×C → {T,F} called the classifier, where C = {c_1,...,c_n} is a predefinedset o f categories and D is a (possibly infinite) set of documents. If Φ(d_j,c_i) = T,then d_j is called a positive example (or a member) of c_i, while if Φ(d_j,c_i) = F itis called a negative example of c_i [2].
Figure 1 is an example, where C = {Graphics,Arch,NLP,AI,Theory}, any document in the document space should be assigned to one of these categories by the function Φ ̂
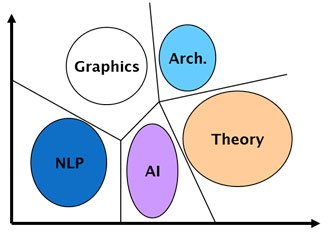
Figure1: TC example