Classification of Arabic Documents
Arabic Text Classification:
The importance of ATC comes from the following main reasons;
Due to Historical, Geographical, Religious reason; Arabic language is a very rich with documents.
A study of the world market, commissioned by the Miniwatts Marketing Group[^3] shows that the number of Arab Internet users in the Middle East and Africa could jumped to 32 million in 2008 from 2.5 million in the year 2000, and in June 2012 this number jumped to more than 90 million users, the growth of Arab Internet users in the Middle East region (for the same period 2000-2012) is expected to reach about 2,640% compared to the growth of the world Internet users.
The conducted research pointed out that 65% of the Internet Arabic speaking users could not read English pages.
The big growth of the Arabic internet content in the last years has raised up the need for an Arabic language processing tools[^4] .
But on the other hand there are many challenges facing the development of Arabic language processing tools including ATC tools. The first is that Arabic is a very rich language with complex morphology. Arabic language belongs to the family of Semitic languages. It differs from Latin languages morphologically,syntactically and semantically. The writing system of Arabic has 25consonants and three long vowels that are written from right to left and change shapesaccording to their position in the word.
In addition, Arabic has short vowels (diacritics)written above and under a consonant to give it its desired sound and hence give a word adesired meaning. The common diacritics used in Arabic language are listed in Table 1[^5] .
Table 1 Common short vowels (diacritics) used in Arabic text

The Arabic language consists of three types of words; nouns, verbs and particles. Nouns and verbs are derived from a limited set of about 10,000 roots[^6] .Templates are applied to the roots in order to derive nounsand verbs by removing letters, adding letters, or includinginfixes. Furthermore, a stem may accept prefixes and/orsuffixes in order to form the word[^7] . So, Arabic language is highly derivative where tens or even hundreds of words could be formed using only one root. Furthermore, a single word may be derived from multiple roots[^8] .
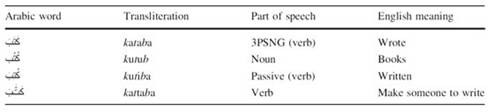
In addition, it is very common to use diacritics (fully, partially even randomly) with classical poetry, children’s literature and in ordinary text when it is ambiguous to read. For instance, a word in Arabic consisting of three consonants like ( كتب ktb) “to write” canhave many interpretations with the presence of diacritics[^9] such as shown in Table 2.
For Arabic language speakers, the only way to disambiguate the diacritic-less words isto locate them within the context. Analysis of 23,000 Arabic scripts showed that there is anaverage of 11.6 possible ways to assign diacritics for every diacritic-less word[^10] .
Table 2 Different interpretation of the Arabic word كتب (ktb) in the presence of diacritics
In addition to the above description of complex morphology, Arabic has very complex syntaxes, linguistic and grammatical rules.
It is clear that Arabic language has a very different and difficult structure than other languages. These differences makeit hard for language processing techniques made for other language to directly apply to Arabic.
So the objective of this project is to develop an Arabic Text-Document Classifier (ATC), and study the different techniques and parameters that may affect the performance of this classifier. In this project we will build ATC model and discus its implementation problems and decisions. Also we will use multiple classification techniques, namely support vector machine, Naive Bayes, k-Nearest Neighbors, and decision trees. We will compare between them from the accuracy and processing time perspectives. This project can be then used as a base for other students who want to continue in this field to make deeper studies.